Labo 2 : Equipements réseaux virtuels basé sur les namespaces Linux
Les namespaces permettent une virtualisation extrêmement légère et sans nécessité de support par le matériel au niveau du CPU : conceptuellement, il s’agit d’une simple indirection logicielle supplémentaire associée à un processus, implémentée au sein du noyau du système d’exploitation.
Concrètement, si on se réfère uniquement à la pile TCP/IP, on peut probablement instancier des dizaines de milliers de piles TCP/IP indépendantes sur un PC typique, alors qu’on sera rapidement limité à une centaine de VM si on virtualise l’ensemble de la machine avec qemu, virtualbox ou autre.
Dans ce laboratoire, nous allons mettre en oeuvre les namespaces réseau linux au travers de la commande ip du package debian iproute2. Ils permettent d’instancier une pile TCP/IP entière et de l’associer à un ensemble de processus, c’est à dire virtualiser au niveau de l’OS une ressource dédiée uniquement au réseau. Nous utiliserons cette fonctionnalité pour instancier un routeur virtuel hosté par un autre routeur en se basant sur les namespaces réseaux du kernel Linux.
Ce laboratoire est divisé en 3 parties :
Préparation de la configuration du routage et de l’adressage de la topologie sans routeur virtuel.
Mise en oeuvre des namespaces réseau sous Linux pour instancier un routeur dans un routeur.
Implémenter une variante basée sur les bridges en instanciant un routeur virtuel dont les interfaces réseaux sont bridgées avec celles de l’hôte.
Généraliser l’idée à deux routeurs virtuels exécutés sur la même machine.
1 - Topologie
Téléchargez le labo router_in_router. Vous devriez obtenir la topologie indiquée en figure Fig. 6. Utilisez votre script écrit dans le labo précédent pour installer l’accès SSH sur les machines R1 et H1 et leur donner un hostname correspondant à celui indiqué sur la topologie.
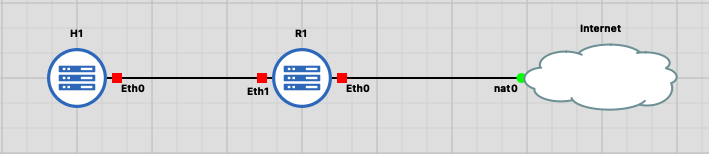
Fig. 6 Topologie d’un routeur dans un routeur
A - Préparation du routeur hôte
Dans un premier temps, la topogie indiquée par GNS3 correspondra exactement au réseau qu’on veut constuire : un hôte H1 connecté à R1 qui est un routeur et une passerelle NAT en direction du nuage Internet.
Vous écrirez un shell script bash exécuté depuis votre machine, qui mettra en place la configuration suivante, en partant du labo initial importé dans GNS3.
Installation de tcpdump sur H1 et R1 avec la commande
apt install -y tcpdump.Comme R1 est un routeur, il forwarde des paquets et devra avoir
/proc/sys/net/ipv4/ip_forwardposé à 1.L’IP obtenue par R1 coté
eth0sera obtenue par DHCP avec la commandedhclient -v eth0, car un serveur DHCP est disponible coténat0L’IP de R1 coté
eth1et de H1eth0sera configurée statiquement aveciproute2, dans le segment IP10.0.0.0/24. La configuration d’une IP avec iproute est disponible dans la documentation 2La route par défaut de H1 passera par R1, référez vous à la documentation d’iproute pour installer une route par défaut 1
R1 implémentera une passerelle NAT à l’aide de nftables pour cela, il faut exécuter le script nftables suivant sur R1
#!/usr/sbin/nft -f flush ruleset table ip nat { chain masq { type nat hook postrouting priority 100; oifname "eth0" counter masquerade } }
Ce script dit simplement que tout paquet routé sur l’interface eth0 devra avoir son adresse IP source modifiée par l’IP de cette interface.
B - Vérification du bon fonctionnement
A la fin de cette implémentation, H1 doit pouvoir accéder à Internet, vérifiez le avec la commande ping suivante
ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=55 time=3.99 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=55 time=2.93 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=55 time=3.05 ms
Attention : Il est possible de pinger la destination sans passer par R1, car les équipements disposent d’une interface de management, mgmt0 qui donne accès à Internet si elle est pointée par la route par défaut. Pour être sûr que mgmt0 n’est pas utilisé pour sortir sur Internet, on peut le vérifier avec la commande traceroute
root@H1:~# traceroute -n 1.1.1.1
traceroute to 1.1.1.1 (1.1.1.1), 30 hops max, 60 byte packets
1 10.0.0.1 1.170 ms 0.883 ms 0.694 ms
2 172.21.1.1 1.783 ms 1.614 ms 1.443 m
2 - Routeur virtuel routé
A - Préparation
Dans un deuxième temps, il faudra instancier un routeur dans R1, sur la base des namespaces réseaux et des interfaces de type veth 4 vus en cours, en utilisant aussi la commande iproute2 5 et sans modifier la topologie indiquée par GNS3 car elle représente, en quelque sorte, la topologie physique de notre laboratoire.
Le routeur R2 existera uniquement par la création d’un nouveau namespace réseau appelé ns2, les autres namespaces resterons attachés à la machine hôte.

Fig. 7 Rajout d’un routeur dans R1
La figure Fig. 7 illustre le schéma de la nouvelle topologie. Les paquets, plutôt que de passer directement de l’interface eth1 à l’interface eth0 seront :
redirigés vers R2 au travers d’interfaces virtuelles de type
vethcréées aveciproute2.source natés par R2 sur l’interface
veth0, de la même manière que dans la partie précédente, pour permettre une connexion de bout en bout vers Internet.
Les sous-réseaux du routeur R2 seront les suivants :
sur le lien
veth0-veth0: 192.168.0.0/24sur le lien
veth1-veth1: 192.168.1.0/24
Comme le trafic transite par un routeur virtuel présent sur l’hôte R1, il faut pouvoir distinguer le trafic qui provient de l’hôte du trafic qui provient de R2 au niveau de la destination par défaut. Pour cela nous utiliserons le policy routing et ip rule 3 de la manière suivante sur R1
# Effacement de la route par défaut obtenue par dhclient.
ip route delete default
# Redirection des paquets via l'interface veth qui mène à R2.
ip route add default via 192.168.1.1
# Utilisation du policy routing pour passer par eth0 si le trafic vient de R2.
# 172.21.1.1 est la passerelle obtenue par DHCP sur le Nuage Internet.
echo 100 custom >> /etc/iproute2/rt_tables
ip rule add iif veth0 table custom
ip route add default via 172.21.1.1 table custom
N’oubliez pas de rajouter une route vers le réseau 10.0.0.0/24 dans R2, qui passe par une interface différente que celle par défaut, autrement les paquets ne pourrons que sortir de H1, mais pas revenir.
Vous écrirez un shell script qui met en place cette configuration, le shell script sera à fournir dans votre carnet de laboratoire.
B - Vérification du bon fonctionnement
A la fin de cette implémentation, H1 doit toujours pouvoir accéder à Internet, avec une différence importante : ses paquets transiteront par R2.
Pour le démontrer vous fournirez une capture d’écran de l’exécution de tcpdump dans le namespace de R2 et dans le namespace de R1,
en même temps qu’un ping vers 1.1.1.1 depuis H1.
Les paquets qui sortent de
veth0devront être source natés avec l’IP assignée à R2 sur veth1.Le TTL des paquets qui sortent de
eth0sur R1 devra être décrémenté trois fois par rapport à ceux qui entrent sureth1depuis H1, car ils traversent en réalité 3 piles TCP/IP comme indiqué sur la figure Fig. 8 : l’une entreeth1etveth1, c’est à dire en entrant sur R2, l’autre entreveth0etheth0, c’est à dire en sortant de R2, et la dernière en sortant de R1.

Fig. 8 Décrément du TTL avec un routeur virtuel
Lorsque R2 n’est pas utilisé, le TTL des paquets est incrémenté de 2 (valeur 55) pas rapport à lorsqu’il n’est pas utilisé (valeur 53), expliquez pourquoi ?
# Sans utiliser R2 root@H1:~# ping 1.1.1.1 PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data. 64 bytes from 1.1.1.1: icmp_seq=1 ttl=55 time=3.78 ms 64 bytes from 1.1.1.1: icmp_seq=2 ttl=55 time=2.95 ms # En utilisant R2 root@H1:~# ping 1.1.1.1 PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data. 64 bytes from 1.1.1.1: icmp_seq=1 ttl=53 time=4.71 ms 64 bytes from 1.1.1.1: icmp_seq=2 ttl=53 time=3.28 ms 64 bytes from 1.1.1.1: icmp_seq=3 ttl=53 time=3.24 ms 64 bytes from 1.1.1.1: icmp_seq=4 ttl=53 time=3.25 ms
3 - Routeur virtuel bridgé
Effacer toute la configuration précédente, qui n’a rien a voir avec celle qu’on va implémenter maintenant. Pour ce faire, le mieux est d’importer à nouveau le labo dans GNS3.

Fig. 9 Routeur bridgé physiquement
La configuration est schématisée sur la figure Fig. 9. Cette fois, nous implémenterons routeur virtuel en bridgant les interfaces veth directement sur les interfaces physique eth1 eth0. Ceci aura pour effet d’isoler la pile TCP/IP du routeur, mais de présenter ses interfaces sur le même domaine de broadcast que H1 et le noeud qui fournit Internet. L’avantage de cette configuration est qu’elle ne nécessite pas de faire du policy routing.
Concrètement ceci veut dire que la configuration de ce routeur virtuel sera identifique à celle présentée dans la partie A - Préparation du routeur hôte, sauf que toute la configuration aura lieu dans le namespace ns2 et que les interfaces connectées à un routeur ne sont plus les interfaces eth0 ou eth1 mais les interfaces veth0 et veth1.
Donner dans votre carnet de laboratoire les scripts utilisés pour réaliser cette configuration.
Donner une capture d’écran une suite de commande qui montre que la configuration du routeur tourne bien dans une instance à part.
Avec cette configuration, le TTL ne devrait être décrémenté qu’une seule fois, c’est à dire lorsqu’il traverse la pile TCP/IP du routeur instancié dans ns2:
# Sans utiliser R1, mais en passant par R2 hosté sur R1.
root@H1:~# ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=55 time=3.78 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=55 time=2.95 ms
4 - Instanciation de plusieurs routeurs virtuels sur R1
Dans cette dernière étape, vous mettrez en place deux routeurs virtuels R2 et R3, sur la base des scripts écrits précédemment. La figure Fig. 10 illustre la topologie qu’on veut implémenter : Les paquets qui proviennent de H1 traverserons R2 et R3 avant d’être envoyés en sortie.

Fig. 10 Deux routeurs virtuels basés sur les namespaces
Les interfaces
vethcoté hôtes pourrons être bridgées ou routées, selon votre préférence.Vous fournirez le script bash pour pour construire cette topologie, en supposant qu’on part du labo initial importé dans GNS3 et sur les machines sont toutes présentes dans ssh_config.
Votre cahier de laboratoire devra fournir les captures d’écran des ping et wireshark associés qui démontrent que la topologie est fonctionnelle, c’est à dire que le trafic passe bien par R2 et R3 avant de ressortir de R1.